Künstiliche Intelligenz als Ersatz für Tierversuche
Written on July 13th, 2020 by Tuan TranJedes Jahr werden allein in den USA mehr als einhundert Millionen Tiere, darunter Mäuse, Ratten, Frösche, Hunde, Katzen, Kaninchen, Hamster, Meerschweinchen, Affen, Fische und Vögel während grausamer Tierversuche getötet. Sie werden jedoch dabei nicht nur getötet, sondern mit verschiedenen Tests brutal gequält, vergiftet, geblendet, zum Einatmen von Giftstoffen gezwungen oder dazu gebracht, giftige Gase und verschiedene andere Dinge einzuatmen.
In letzter Zeit wurden jedoch viele Versuche unternommen, um die Tierquälerei durch Versuche zu verhindern. Einer der Versuche ist der Einsatz künstlicher Intelligenz, um Tierversuche vollständig zu ersetzen.
RASAR
Rasar steht für "Read-Across Structure Activity Relationships" und ist der Name einer KI-unterstützten Software. Es geht dabei nicht nur darum Tierversuche zu simulieren, sondern diese KI kann die Ergebnisse der neun an den häufigsten durchgeführten Tierversuchen mit einer sehr hohen Wahrscheinlichkeit vorhersagen. In einigen Fällen bringt die KI sogar bessere Ergebnisse als die Tierversuche selbst. Neun Tierversuche klingen zwar wenig, aber diese neun sind zusammen machen insgesamt 57% aller Tierversuche aus.
Wie funktioniert RASAR?
Die KI selbst kann in zwei Arten unterschieden werden. Die Entwickler nennen diese "Simple RASAR" und "Data Fusion RASAR". Im ersten Schritt, dem "Unsuperwised Learning" verwendet RASAR binäre Fingerabdrücke und die Jaccard-Distanz, um chemische Ähnlichkeit zu definieren. Aus dieser Ähnlichkeitsmetrik wurde eine große chemische Ähnlichkeitsadjazenzmatrix konstruiert und zur Ableitung von Merkmalsvektoren für überwachtes Lernen verwendet. Bei einer gegebenen Liste von Chemikalien sagt sie voraus, ob eine Chemikalie toxisch ist oder nicht. Derzeit kann sie dies für Zehntausende von Chemikalien vorhersagen.
Um diese Matrix zu erstellen wurden 10 Millionen chemische Strukturen analysiert und insgesamt ergaben sich etwa 50 Milliarden möglicher Kombinationen von Paaren. Ein Supercomputer vergleicht dabei 74 ausgewählte Eigenschaften der Chemikalien miteinander und erstellt daraus eine Karte. Je ähnlicher zwei Chemikalien sich sind, desto näher sind sie beieinander.
Wie funktioniert nun das Simple RASAR?
Die vorher generierte Karte kann auf einfache Weise zwei bereits bekannte Paarkombinationen analysieren und vorhersagen, in wie weit diese schädlich sind. Was man aber eigentlich erreichen will ist vorherzusagen, wie zwei unbekannte Paare aufeinander reagieren.
Das Simple RASAR nutzt die sogenannte "Logistic Regression". Es werden dabei zwei bisher unbekannte Chemikalien genommen, welche ähnliche Eigenschaften haben und dann eine Wahrscheinlichkeit berechnet wie schädlich diese Kombination ist.
Um es ganz einfach auszudrücken funktioniert es so wie die "Recommender Systems" von Netflix oder anderen Streamingdiensten. Wenn beispielsweise Person A "Star Wars" mag, Person B auch "Star Wars" und "Harry Potter" mag, dann haben wir erstmal eine bekannte Relation zwischen A und B. Nun gibt es noch eine Person C. Diese mag ebenfalls "Harry Potter" und dann noch "Titanic". Da A und B, und B und C ähnliche vorlieben haben, wird Netflix der Person A nun "Titanic" empfehlen, da A und C einen gemeinsamen Nenner haben, die sich ähnlich sind.
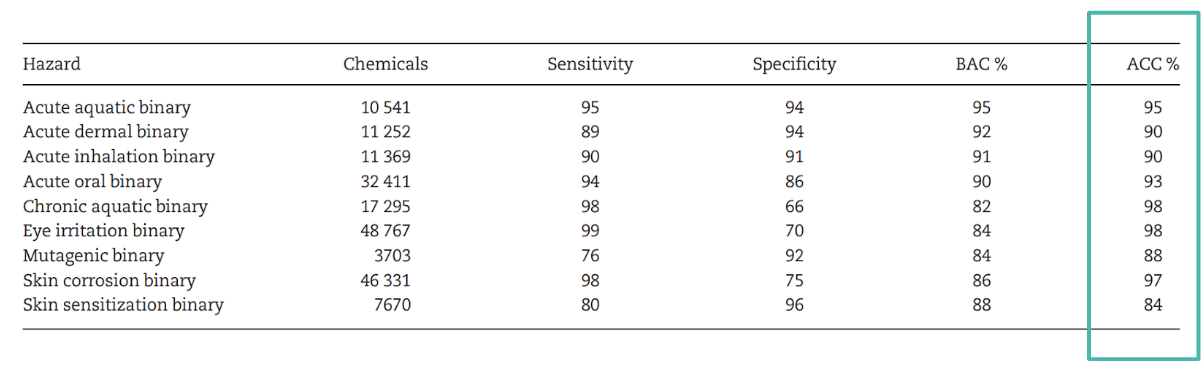
Bei dem Simple RASAR ist es dann auch so ähnlich. Wenn die Chemikalie A und B zusammen Hautirritationen verursachen. Die Chemikalien B und C ebenfalls, dann ist es gut möglich, dass A und C auch zu Irritationen führen (siehe Bild 1). Wie akkurat diese Methode ist, kann man in dieser Tabelle sehen. Das sind die neun meist angewandten Tierversuche und die Genauigkeit entspricht dabei etwa realen Tierversuchen. Hierbei musste jedoch kein Tier leiden.


Data Fusion RASAR
Nur genauso gut zu sein wie Tierversuche reicht jedoch nicht, da 60-70% Genauigkeit nicht wirklich sicher ist. Eine höhere Genauigkeit erzielt man mit Data Fusion. Anders als bei Simple RASAR, was immer nur eine Eigenschaft vergleich, und auch nur Paare vergleich, die nah einander auf der Karte liegen, Nimmt mehrere Eigenschaften zufällig und vergleich auch zwei zufällig ausgewählte Chemikalien. Sie macht sich das sogenannte "Random Forest" zu nutzen. Im Prinzip nimmt es mehrere Entscheidungszweige (Baum) und vergleicht es mit anderen Zweigen, wodurch ein Wald entsteht. Funktionieren tut es so:
Angenommen man möchte wissen, mit welcher unbekannten Chemikalie X gekoppelt werden muss, damit eine Hautirritation entsteht. Aus vorherigen Ergebnissen weiß man, dass man bei Kombination mit Y; X und Y eine sehr hohe Wahrscheinlichkeit haben, eine Hautirritation zu verursachen. Nun nimmt man zufälligerweise einiger deren Eigenschaften und merkt sie sich. Jetzt ganz einfach ausgedrückt, stellt X anderen Chemikalien die Frage "Hey, mit welchen Chemikalien habe ich die Eigenschaften XYZ gemeinsam?". X erhält dann Antworten, die in einem Entscheidungsbaum enden. Da X das mehrmals macht, entstehen mehrere Bäume, und somit ein Wald, woher auch der Name kommt. Nun vergleicht X alle Bäume miteinander und guckt, welche Chemikalie am häufigsten vorkam. In diesem Beispiel ist es jetzt die Chemikalie B. Aus diesem Ergebnis folgt X dann, dass es bei Verwendung mit B, Hautirritationen verursachen kann. Eine kurze Veranschaulichung und die Ergebnisse können in Bild 2 und Tabelle 2 gefunden werden.

Zusammenfassung
KI kann also nicht nur Ergebnisse genausogut vorhersagen, sondern sogar besser beurteilen. Mit KI muss ebenfalls kein Tier leiden und hat keine Nachteile. Die Berechnung des Initialen Schrittes für die Erstellung der Karte, welche dann von Simple und Data Fusion genutzt werden kann, kostet rund 5000$. Das bauen der Karte muss aber nur einmal gemacht werden. Berechnungen für Simple und Data Fusion kosten dann nicht mal mehr einen Bruchteil davon und können immer wieder durchgeführt werden. Zwar klingen 5000$ viel, aber im Vergleich zu 100.000.000$ die für Tierversuche allein in den USA ausgegeben werden ist dieser Wert ziemlich lachhaft.
https://medium.com/@Synced/how-random-forest-algorithm-works-in-machine-learning-3c0fe15b6674
https://towardsdatascience.com/understanding-random-forest-58381e0602d2
https://dataaspirant.com/2017/05/22/random-forest-algorithm-machine-learing/